Feature engineering#
Introduction to Xarray#
In this lesson, we discuss cover the basics of Xarray data structures. By the end of the lesson, we will be able to:
Understand the basic data structures in Xarray
Inspect
DataArrayandDatasetobjects.Read and write netCDF files using Xarray.
Understand that there are many packages that build on top of xarray
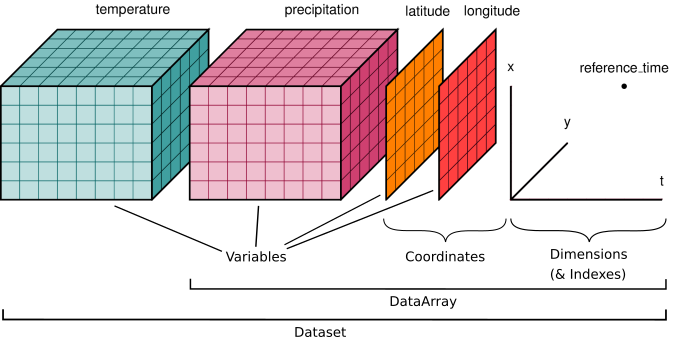
Data structures#
We’ll start by reviewing the various components of the Xarray data model, represented here visually:
Xarray has a few small real-world tutorial datasets hosted in the xarray-data GitHub repository.
xarray.tutorial.load_dataset is a convenience function to download and open DataSets by name (listed at that link).
Here we’ll use air temperature from the National Center for Environmental Prediction.
import matplotlib.pyplot as plt
import numpy as np
import xarray as xr
ds = xr.tutorial.load_dataset("air_temperature")
Xarray objects have convenient HTML representations to give an overview of what we’re working with:
ds
<xarray.Dataset> Size: 31MB
Dimensions: (lat: 25, time: 2920, lon: 53)
Coordinates:
* lat (lat) float32 100B 75.0 72.5 70.0 67.5 65.0 ... 22.5 20.0 17.5 15.0
* lon (lon) float32 212B 200.0 202.5 205.0 207.5 ... 325.0 327.5 330.0
* time (time) datetime64[ns] 23kB 2013-01-01 ... 2014-12-31T18:00:00
Data variables:
air (time, lat, lon) float64 31MB 241.2 242.5 243.5 ... 296.2 295.7
Attributes:
Conventions: COARDS
title: 4x daily NMC reanalysis (1948)
description: Data is from NMC initialized reanalysis\n(4x/day). These a...
platform: Model
references: http://www.esrl.noaa.gov/psd/data/gridded/data.ncep.reanaly...Note that behind the scenes the tutorial.open_dataset downloads a file. It then uses xarray.open_dataset function to open that file (which for this datasets is a netCDF file).
A few things are done automatically upon opening, but controlled by keyword arguments. For example, try passing the keyword argument mask_and_scale=False… what happens?
What’s in a Dataset?#
Datasets are dictionary-like containers of DataArrays. They are a mapping of variable name to DataArray:
# pull out "air" dataarray with dictionary syntax
ds["air"]
<xarray.DataArray 'air' (time: 2920, lat: 25, lon: 53)> Size: 31MB
array([[[241.2 , 242.5 , 243.5 , ..., 232.8 , 235.5 , 238.6 ],
[243.8 , 244.5 , 244.7 , ..., 232.8 , 235.3 , 239.3 ],
[250. , 249.8 , 248.89, ..., 233.2 , 236.39, 241.7 ],
...,
[296.6 , 296.2 , 296.4 , ..., 295.4 , 295.1 , 294.7 ],
[295.9 , 296.2 , 296.79, ..., 295.9 , 295.9 , 295.2 ],
[296.29, 296.79, 297.1 , ..., 296.9 , 296.79, 296.6 ]],
[[242.1 , 242.7 , 243.1 , ..., 232. , 233.6 , 235.8 ],
[243.6 , 244.1 , 244.2 , ..., 231. , 232.5 , 235.7 ],
[253.2 , 252.89, 252.1 , ..., 230.8 , 233.39, 238.5 ],
...,
[296.4 , 295.9 , 296.2 , ..., 295.4 , 295.1 , 294.79],
[296.2 , 296.7 , 296.79, ..., 295.6 , 295.5 , 295.1 ],
[296.29, 297.2 , 297.4 , ..., 296.4 , 296.4 , 296.6 ]],
[[242.3 , 242.2 , 242.3 , ..., 234.3 , 236.1 , 238.7 ],
[244.6 , 244.39, 244. , ..., 230.3 , 232. , 235.7 ],
[256.2 , 255.5 , 254.2 , ..., 231.2 , 233.2 , 238.2 ],
...,
...
...,
[294.79, 295.29, 297.49, ..., 295.49, 295.39, 294.69],
[296.79, 297.89, 298.29, ..., 295.49, 295.49, 294.79],
[298.19, 299.19, 298.79, ..., 296.09, 295.79, 295.79]],
[[245.79, 244.79, 243.49, ..., 243.29, 243.99, 244.79],
[249.89, 249.29, 248.49, ..., 241.29, 242.49, 244.29],
[262.39, 261.79, 261.29, ..., 240.49, 243.09, 246.89],
...,
[293.69, 293.89, 295.39, ..., 295.09, 294.69, 294.29],
[296.29, 297.19, 297.59, ..., 295.29, 295.09, 294.39],
[297.79, 298.39, 298.49, ..., 295.69, 295.49, 295.19]],
[[245.09, 244.29, 243.29, ..., 241.69, 241.49, 241.79],
[249.89, 249.29, 248.39, ..., 239.59, 240.29, 241.69],
[262.99, 262.19, 261.39, ..., 239.89, 242.59, 246.29],
...,
[293.79, 293.69, 295.09, ..., 295.29, 295.09, 294.69],
[296.09, 296.89, 297.19, ..., 295.69, 295.69, 295.19],
[297.69, 298.09, 298.09, ..., 296.49, 296.19, 295.69]]])
Coordinates:
* lat (lat) float32 100B 75.0 72.5 70.0 67.5 65.0 ... 22.5 20.0 17.5 15.0
* lon (lon) float32 212B 200.0 202.5 205.0 207.5 ... 325.0 327.5 330.0
* time (time) datetime64[ns] 23kB 2013-01-01 ... 2014-12-31T18:00:00
Attributes:
long_name: 4xDaily Air temperature at sigma level 995
units: degK
precision: 2
GRIB_id: 11
GRIB_name: TMP
var_desc: Air temperature
dataset: NMC Reanalysis
level_desc: Surface
statistic: Individual Obs
parent_stat: Other
actual_range: [185.16 322.1 ]You can save some typing by using the “attribute” or “dot” notation. This won’t
work for variable names that clash with a built-in method name (like mean for
example).
# pull out dataarray using dot notation
ds.air
<xarray.DataArray 'air' (time: 2920, lat: 25, lon: 53)> Size: 31MB
array([[[241.2 , 242.5 , 243.5 , ..., 232.8 , 235.5 , 238.6 ],
[243.8 , 244.5 , 244.7 , ..., 232.8 , 235.3 , 239.3 ],
[250. , 249.8 , 248.89, ..., 233.2 , 236.39, 241.7 ],
...,
[296.6 , 296.2 , 296.4 , ..., 295.4 , 295.1 , 294.7 ],
[295.9 , 296.2 , 296.79, ..., 295.9 , 295.9 , 295.2 ],
[296.29, 296.79, 297.1 , ..., 296.9 , 296.79, 296.6 ]],
[[242.1 , 242.7 , 243.1 , ..., 232. , 233.6 , 235.8 ],
[243.6 , 244.1 , 244.2 , ..., 231. , 232.5 , 235.7 ],
[253.2 , 252.89, 252.1 , ..., 230.8 , 233.39, 238.5 ],
...,
[296.4 , 295.9 , 296.2 , ..., 295.4 , 295.1 , 294.79],
[296.2 , 296.7 , 296.79, ..., 295.6 , 295.5 , 295.1 ],
[296.29, 297.2 , 297.4 , ..., 296.4 , 296.4 , 296.6 ]],
[[242.3 , 242.2 , 242.3 , ..., 234.3 , 236.1 , 238.7 ],
[244.6 , 244.39, 244. , ..., 230.3 , 232. , 235.7 ],
[256.2 , 255.5 , 254.2 , ..., 231.2 , 233.2 , 238.2 ],
...,
...
...,
[294.79, 295.29, 297.49, ..., 295.49, 295.39, 294.69],
[296.79, 297.89, 298.29, ..., 295.49, 295.49, 294.79],
[298.19, 299.19, 298.79, ..., 296.09, 295.79, 295.79]],
[[245.79, 244.79, 243.49, ..., 243.29, 243.99, 244.79],
[249.89, 249.29, 248.49, ..., 241.29, 242.49, 244.29],
[262.39, 261.79, 261.29, ..., 240.49, 243.09, 246.89],
...,
[293.69, 293.89, 295.39, ..., 295.09, 294.69, 294.29],
[296.29, 297.19, 297.59, ..., 295.29, 295.09, 294.39],
[297.79, 298.39, 298.49, ..., 295.69, 295.49, 295.19]],
[[245.09, 244.29, 243.29, ..., 241.69, 241.49, 241.79],
[249.89, 249.29, 248.39, ..., 239.59, 240.29, 241.69],
[262.99, 262.19, 261.39, ..., 239.89, 242.59, 246.29],
...,
[293.79, 293.69, 295.09, ..., 295.29, 295.09, 294.69],
[296.09, 296.89, 297.19, ..., 295.69, 295.69, 295.19],
[297.69, 298.09, 298.09, ..., 296.49, 296.19, 295.69]]])
Coordinates:
* lat (lat) float32 100B 75.0 72.5 70.0 67.5 65.0 ... 22.5 20.0 17.5 15.0
* lon (lon) float32 212B 200.0 202.5 205.0 207.5 ... 325.0 327.5 330.0
* time (time) datetime64[ns] 23kB 2013-01-01 ... 2014-12-31T18:00:00
Attributes:
long_name: 4xDaily Air temperature at sigma level 995
units: degK
precision: 2
GRIB_id: 11
GRIB_name: TMP
var_desc: Air temperature
dataset: NMC Reanalysis
level_desc: Surface
statistic: Individual Obs
parent_stat: Other
actual_range: [185.16 322.1 ]What’s in a DataArray?#
data + (a lot of) metadata
Named dimensions#
.dims correspond to the axes of your data.
In this case we have 2 spatial dimensions (latitude and longitude are store with shorthand names lat and lon) and one temporal dimension (time).
ds.air.dims
('time', 'lat', 'lon')
Coordinate variables#
.coords is a simple data container
for coordinate variables.
Here we see the actual timestamps and spatial positions of our air temperature data:
ds.air.coords
Coordinates:
* lat (lat) float32 100B 75.0 72.5 70.0 67.5 65.0 ... 22.5 20.0 17.5 15.0
* lon (lon) float32 212B 200.0 202.5 205.0 207.5 ... 325.0 327.5 330.0
* time (time) datetime64[ns] 23kB 2013-01-01 ... 2014-12-31T18:00:00
Coordinates objects support similar indexing notation
# extracting coordinate variables
ds.air.lon
<xarray.DataArray 'lon' (lon: 53)> Size: 212B
array([200. , 202.5, 205. , 207.5, 210. , 212.5, 215. , 217.5, 220. , 222.5,
225. , 227.5, 230. , 232.5, 235. , 237.5, 240. , 242.5, 245. , 247.5,
250. , 252.5, 255. , 257.5, 260. , 262.5, 265. , 267.5, 270. , 272.5,
275. , 277.5, 280. , 282.5, 285. , 287.5, 290. , 292.5, 295. , 297.5,
300. , 302.5, 305. , 307.5, 310. , 312.5, 315. , 317.5, 320. , 322.5,
325. , 327.5, 330. ], dtype=float32)
Coordinates:
* lon (lon) float32 212B 200.0 202.5 205.0 207.5 ... 325.0 327.5 330.0
Attributes:
standard_name: longitude
long_name: Longitude
units: degrees_east
axis: X# extracting coordinate variables from .coords
ds.coords["lon"]
<xarray.DataArray 'lon' (lon: 53)> Size: 212B
array([200. , 202.5, 205. , 207.5, 210. , 212.5, 215. , 217.5, 220. , 222.5,
225. , 227.5, 230. , 232.5, 235. , 237.5, 240. , 242.5, 245. , 247.5,
250. , 252.5, 255. , 257.5, 260. , 262.5, 265. , 267.5, 270. , 272.5,
275. , 277.5, 280. , 282.5, 285. , 287.5, 290. , 292.5, 295. , 297.5,
300. , 302.5, 305. , 307.5, 310. , 312.5, 315. , 317.5, 320. , 322.5,
325. , 327.5, 330. ], dtype=float32)
Coordinates:
* lon (lon) float32 212B 200.0 202.5 205.0 207.5 ... 325.0 327.5 330.0
Attributes:
standard_name: longitude
long_name: Longitude
units: degrees_east
axis: XIt is useful to think of the values in these coordinate variables as axis “labels” such as “tick labels” in a figure. These are coordinate locations on a grid at which you have data.
Arbitrary attributes#
.attrs is a dictionary that can contain arbitrary Python objects (strings, lists, integers, dictionaries, etc.) Your only
limitation is that some attributes may not be writeable to certain file formats.
ds.air.attrs
{'long_name': '4xDaily Air temperature at sigma level 995',
'units': 'degK',
'precision': 2,
'GRIB_id': 11,
'GRIB_name': 'TMP',
'var_desc': 'Air temperature',
'dataset': 'NMC Reanalysis',
'level_desc': 'Surface',
'statistic': 'Individual Obs',
'parent_stat': 'Other',
'actual_range': array([185.16, 322.1 ], dtype=float32)}
# assign your own attributes!
ds.air.attrs["modified_with"] = "xarray"
ds.air.attrs
{'long_name': '4xDaily Air temperature at sigma level 995',
'units': 'degK',
'precision': 2,
'GRIB_id': 11,
'GRIB_name': 'TMP',
'var_desc': 'Air temperature',
'dataset': 'NMC Reanalysis',
'level_desc': 'Surface',
'statistic': 'Individual Obs',
'parent_stat': 'Other',
'actual_range': array([185.16, 322.1 ], dtype=float32),
'modified_with': 'xarray'}
ds.air
<xarray.DataArray 'air' (time: 2920, lat: 25, lon: 53)> Size: 31MB
array([[[241.2 , 242.5 , 243.5 , ..., 232.8 , 235.5 , 238.6 ],
[243.8 , 244.5 , 244.7 , ..., 232.8 , 235.3 , 239.3 ],
[250. , 249.8 , 248.89, ..., 233.2 , 236.39, 241.7 ],
...,
[296.6 , 296.2 , 296.4 , ..., 295.4 , 295.1 , 294.7 ],
[295.9 , 296.2 , 296.79, ..., 295.9 , 295.9 , 295.2 ],
[296.29, 296.79, 297.1 , ..., 296.9 , 296.79, 296.6 ]],
[[242.1 , 242.7 , 243.1 , ..., 232. , 233.6 , 235.8 ],
[243.6 , 244.1 , 244.2 , ..., 231. , 232.5 , 235.7 ],
[253.2 , 252.89, 252.1 , ..., 230.8 , 233.39, 238.5 ],
...,
[296.4 , 295.9 , 296.2 , ..., 295.4 , 295.1 , 294.79],
[296.2 , 296.7 , 296.79, ..., 295.6 , 295.5 , 295.1 ],
[296.29, 297.2 , 297.4 , ..., 296.4 , 296.4 , 296.6 ]],
[[242.3 , 242.2 , 242.3 , ..., 234.3 , 236.1 , 238.7 ],
[244.6 , 244.39, 244. , ..., 230.3 , 232. , 235.7 ],
[256.2 , 255.5 , 254.2 , ..., 231.2 , 233.2 , 238.2 ],
...,
...
...,
[294.79, 295.29, 297.49, ..., 295.49, 295.39, 294.69],
[296.79, 297.89, 298.29, ..., 295.49, 295.49, 294.79],
[298.19, 299.19, 298.79, ..., 296.09, 295.79, 295.79]],
[[245.79, 244.79, 243.49, ..., 243.29, 243.99, 244.79],
[249.89, 249.29, 248.49, ..., 241.29, 242.49, 244.29],
[262.39, 261.79, 261.29, ..., 240.49, 243.09, 246.89],
...,
[293.69, 293.89, 295.39, ..., 295.09, 294.69, 294.29],
[296.29, 297.19, 297.59, ..., 295.29, 295.09, 294.39],
[297.79, 298.39, 298.49, ..., 295.69, 295.49, 295.19]],
[[245.09, 244.29, 243.29, ..., 241.69, 241.49, 241.79],
[249.89, 249.29, 248.39, ..., 239.59, 240.29, 241.69],
[262.99, 262.19, 261.39, ..., 239.89, 242.59, 246.29],
...,
[293.79, 293.69, 295.09, ..., 295.29, 295.09, 294.69],
[296.09, 296.89, 297.19, ..., 295.69, 295.69, 295.19],
[297.69, 298.09, 298.09, ..., 296.49, 296.19, 295.69]]])
Coordinates:
* lat (lat) float32 100B 75.0 72.5 70.0 67.5 65.0 ... 22.5 20.0 17.5 15.0
* lon (lon) float32 212B 200.0 202.5 205.0 207.5 ... 325.0 327.5 330.0
* time (time) datetime64[ns] 23kB 2013-01-01 ... 2014-12-31T18:00:00
Attributes:
long_name: 4xDaily Air temperature at sigma level 995
units: degK
precision: 2
GRIB_id: 11
GRIB_name: TMP
var_desc: Air temperature
dataset: NMC Reanalysis
level_desc: Surface
statistic: Individual Obs
parent_stat: Other
actual_range: [185.16 322.1 ]
modified_with: xarrayUnderlying data#
.data contains the numpy array storing air temperature values.
Xarray structures wrap underlying simpler array-like data structures. This part of Xarray is quite extensible allowing for distributed array, GPU arrays, sparse arrays, arrays with units etc. We’ll briefly look at this later in this tutorial.
ds.air.data
array([[[241.2 , 242.5 , 243.5 , ..., 232.8 , 235.5 , 238.6 ],
[243.8 , 244.5 , 244.7 , ..., 232.8 , 235.3 , 239.3 ],
[250. , 249.8 , 248.89, ..., 233.2 , 236.39, 241.7 ],
...,
[296.6 , 296.2 , 296.4 , ..., 295.4 , 295.1 , 294.7 ],
[295.9 , 296.2 , 296.79, ..., 295.9 , 295.9 , 295.2 ],
[296.29, 296.79, 297.1 , ..., 296.9 , 296.79, 296.6 ]],
[[242.1 , 242.7 , 243.1 , ..., 232. , 233.6 , 235.8 ],
[243.6 , 244.1 , 244.2 , ..., 231. , 232.5 , 235.7 ],
[253.2 , 252.89, 252.1 , ..., 230.8 , 233.39, 238.5 ],
...,
[296.4 , 295.9 , 296.2 , ..., 295.4 , 295.1 , 294.79],
[296.2 , 296.7 , 296.79, ..., 295.6 , 295.5 , 295.1 ],
[296.29, 297.2 , 297.4 , ..., 296.4 , 296.4 , 296.6 ]],
[[242.3 , 242.2 , 242.3 , ..., 234.3 , 236.1 , 238.7 ],
[244.6 , 244.39, 244. , ..., 230.3 , 232. , 235.7 ],
[256.2 , 255.5 , 254.2 , ..., 231.2 , 233.2 , 238.2 ],
...,
[295.6 , 295.4 , 295.4 , ..., 296.29, 295.29, 295. ],
[296.2 , 296.5 , 296.29, ..., 296.4 , 296. , 295.6 ],
[296.4 , 296.29, 296.4 , ..., 297. , 297. , 296.79]],
...,
[[243.49, 242.99, 242.09, ..., 244.19, 244.49, 244.89],
[249.09, 248.99, 248.59, ..., 240.59, 241.29, 242.69],
[262.69, 262.19, 261.69, ..., 239.39, 241.69, 245.19],
...,
[294.79, 295.29, 297.49, ..., 295.49, 295.39, 294.69],
[296.79, 297.89, 298.29, ..., 295.49, 295.49, 294.79],
[298.19, 299.19, 298.79, ..., 296.09, 295.79, 295.79]],
[[245.79, 244.79, 243.49, ..., 243.29, 243.99, 244.79],
[249.89, 249.29, 248.49, ..., 241.29, 242.49, 244.29],
[262.39, 261.79, 261.29, ..., 240.49, 243.09, 246.89],
...,
[293.69, 293.89, 295.39, ..., 295.09, 294.69, 294.29],
[296.29, 297.19, 297.59, ..., 295.29, 295.09, 294.39],
[297.79, 298.39, 298.49, ..., 295.69, 295.49, 295.19]],
[[245.09, 244.29, 243.29, ..., 241.69, 241.49, 241.79],
[249.89, 249.29, 248.39, ..., 239.59, 240.29, 241.69],
[262.99, 262.19, 261.39, ..., 239.89, 242.59, 246.29],
...,
[293.79, 293.69, 295.09, ..., 295.29, 295.09, 294.69],
[296.09, 296.89, 297.19, ..., 295.69, 295.69, 295.19],
[297.69, 298.09, 298.09, ..., 296.49, 296.19, 295.69]]])
# what is the type of the underlying data
type(ds.air.data)
numpy.ndarray
Why Xarray?#
Metadata provides context and provides code that is more legible. This reduces the likelihood of errors from typos and makes analysis more intuitive and fun!
Analysis without xarray:#
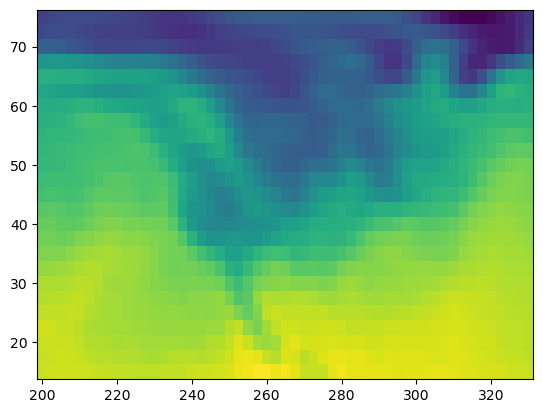
# plot the first timestep
lat = ds.air.lat.data # numpy array
lon = ds.air.lon.data # numpy array
temp = ds.air.data # numpy array
plt.figure()
plt.pcolormesh(lon, lat, temp[0, :, :]);
temp.mean(axis=1) ## what did I just do? I can't tell by looking at this line.
array([[279.398 , 279.6664, 279.6612, ..., 279.9508, 280.3152, 280.6624],
[279.0572, 279.538 , 279.7296, ..., 279.7756, 280.27 , 280.7976],
[279.0104, 279.2808, 279.5508, ..., 279.682 , 280.1976, 280.814 ],
...,
[279.63 , 279.934 , 280.534 , ..., 279.802 , 280.346 , 280.778 ],
[279.398 , 279.666 , 280.318 , ..., 279.766 , 280.342 , 280.834 ],
[279.27 , 279.354 , 279.882 , ..., 279.426 , 279.97 , 280.482 ]])
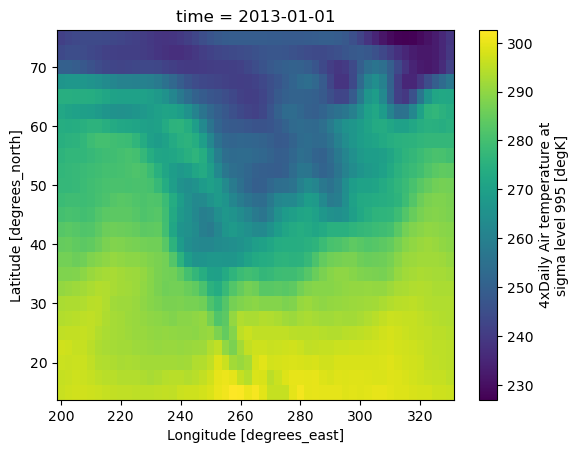
Analysis with xarray#
Much more readable:
ds.air.isel(time=0).plot(x="lon");
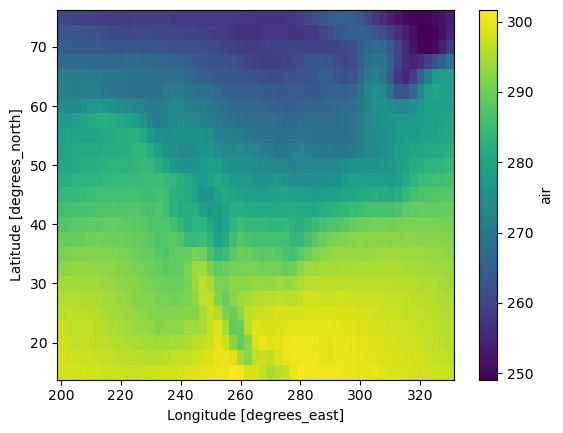
Use dimension names instead of axis numbers
ds.air.mean(dim="time").plot(x="lon")
<matplotlib.collections.QuadMesh at 0x16d4562f0>
Extracting data and indexing#
Xarray supports
label-based indexing using
.selposition-based indexing using
.isel
See the user guide for more.
Label-based indexing#
Xarray inherits its label-based indexing rules from pandas; this means great support for dates and times!
# here's what ds looks like
ds
<xarray.Dataset> Size: 31MB
Dimensions: (lat: 25, time: 2920, lon: 53)
Coordinates:
* lat (lat) float32 100B 75.0 72.5 70.0 67.5 65.0 ... 22.5 20.0 17.5 15.0
* lon (lon) float32 212B 200.0 202.5 205.0 207.5 ... 325.0 327.5 330.0
* time (time) datetime64[ns] 23kB 2013-01-01 ... 2014-12-31T18:00:00
Data variables:
air (time, lat, lon) float64 31MB 241.2 242.5 243.5 ... 296.2 295.7
Attributes:
Conventions: COARDS
title: 4x daily NMC reanalysis (1948)
description: Data is from NMC initialized reanalysis\n(4x/day). These a...
platform: Model
references: http://www.esrl.noaa.gov/psd/data/gridded/data.ncep.reanaly...# pull out data for all of 2013-May
ds.sel(time="2013-05")
<xarray.Dataset> Size: 1MB
Dimensions: (lat: 25, time: 124, lon: 53)
Coordinates:
* lat (lat) float32 100B 75.0 72.5 70.0 67.5 65.0 ... 22.5 20.0 17.5 15.0
* lon (lon) float32 212B 200.0 202.5 205.0 207.5 ... 325.0 327.5 330.0
* time (time) datetime64[ns] 992B 2013-05-01 ... 2013-05-31T18:00:00
Data variables:
air (time, lat, lon) float64 1MB 259.2 259.3 259.1 ... 297.6 297.5
Attributes:
Conventions: COARDS
title: 4x daily NMC reanalysis (1948)
description: Data is from NMC initialized reanalysis\n(4x/day). These a...
platform: Model
references: http://www.esrl.noaa.gov/psd/data/gridded/data.ncep.reanaly...# demonstrate slicing
ds.sel(time=slice("2013-05", "2013-07"))
<xarray.Dataset> Size: 4MB
Dimensions: (lat: 25, time: 368, lon: 53)
Coordinates:
* lat (lat) float32 100B 75.0 72.5 70.0 67.5 65.0 ... 22.5 20.0 17.5 15.0
* lon (lon) float32 212B 200.0 202.5 205.0 207.5 ... 325.0 327.5 330.0
* time (time) datetime64[ns] 3kB 2013-05-01 ... 2013-07-31T18:00:00
Data variables:
air (time, lat, lon) float64 4MB 259.2 259.3 259.1 ... 299.5 299.7
Attributes:
Conventions: COARDS
title: 4x daily NMC reanalysis (1948)
description: Data is from NMC initialized reanalysis\n(4x/day). These a...
platform: Model
references: http://www.esrl.noaa.gov/psd/data/gridded/data.ncep.reanaly...ds.sel(time="2013")
<xarray.Dataset> Size: 15MB
Dimensions: (lat: 25, time: 1460, lon: 53)
Coordinates:
* lat (lat) float32 100B 75.0 72.5 70.0 67.5 65.0 ... 22.5 20.0 17.5 15.0
* lon (lon) float32 212B 200.0 202.5 205.0 207.5 ... 325.0 327.5 330.0
* time (time) datetime64[ns] 12kB 2013-01-01 ... 2013-12-31T18:00:00
Data variables:
air (time, lat, lon) float64 15MB 241.2 242.5 243.5 ... 295.1 294.7
Attributes:
Conventions: COARDS
title: 4x daily NMC reanalysis (1948)
description: Data is from NMC initialized reanalysis\n(4x/day). These a...
platform: Model
references: http://www.esrl.noaa.gov/psd/data/gridded/data.ncep.reanaly...# demonstrate "nearest" indexing
ds.sel(lon=240.2, method="nearest")
<xarray.Dataset> Size: 607kB
Dimensions: (lat: 25, time: 2920)
Coordinates:
* lat (lat) float32 100B 75.0 72.5 70.0 67.5 65.0 ... 22.5 20.0 17.5 15.0
lon float32 4B 240.0
* time (time) datetime64[ns] 23kB 2013-01-01 ... 2014-12-31T18:00:00
Data variables:
air (time, lat) float64 584kB 239.6 237.2 240.1 ... 294.8 296.9 298.4
Attributes:
Conventions: COARDS
title: 4x daily NMC reanalysis (1948)
description: Data is from NMC initialized reanalysis\n(4x/day). These a...
platform: Model
references: http://www.esrl.noaa.gov/psd/data/gridded/data.ncep.reanaly...# "nearest indexing at multiple points"
ds.sel(lon=[240.125, 234], lat=[40.3, 50.3encoded_da], method="nearest")
<xarray.Dataset> Size: 117kB
Dimensions: (lat: 2, time: 2920, lon: 2)
Coordinates:
* lat (lat) float32 8B 40.0 50.0
* lon (lon) float32 8B 240.0 235.0
* time (time) datetime64[ns] 23kB 2013-01-01 ... 2014-12-31T18:00:00
Data variables:
air (time, lat, lon) float64 93kB 268.1 283.0 265.5 ... 256.8 268.6
Attributes:
Conventions: COARDS
title: 4x daily NMC reanalysis (1948)
description: Data is from NMC initialized reanalysis\n(4x/day). These a...
platform: Model
references: http://www.esrl.noaa.gov/psd/data/gridded/data.ncep.reanaly...Position-based indexing#
This is similar to your usual numpy array[0, 2, 3] but with the power of named
dimensions!
ds.air.data[0, 2, 3]
247.5
# pull out time index 0, lat index 2, and lon index 3
ds.air.isel(time=0, lat=2, lon=3) # much better than ds.air[0, 2, 3]
<xarray.DataArray 'air' ()> Size: 8B
array(247.5)
Coordinates:
lat float32 4B 70.0
lon float32 4B 207.5
time datetime64[ns] 8B 2013-01-01
Attributes:
long_name: 4xDaily Air temperature at sigma level 995
units: degK
precision: 2
GRIB_id: 11
GRIB_name: TMP
var_desc: Air temperature
dataset: NMC Reanalysis
level_desc: Surface
statistic: Individual Obs
parent_stat: Other
actual_range: [185.16 322.1 ]
modified_with: xarray# demonstrate slicing
ds.air.isel(lon=slice(-1, 100))
<xarray.DataArray 'air' (time: 2920, lat: 25, lon: 1)> Size: 584kB
array([[[238.6 ],
[239.3 ],
[241.7 ],
...,
[294.7 ],
[295.2 ],
[296.6 ]],
[[235.8 ],
[235.7 ],
[238.5 ],
...,
[294.79],
[295.1 ],
[296.6 ]],
[[238.7 ],
[235.7 ],
[238.2 ],
...,
...
...,
[294.69],
[294.79],
[295.79]],
[[244.79],
[244.29],
[246.89],
...,
[294.29],
[294.39],
[295.19]],
[[241.79],
[241.69],
[246.29],
...,
[294.69],
[295.19],
[295.69]]])
Coordinates:
* lat (lat) float32 100B 75.0 72.5 70.0 67.5 65.0 ... 22.5 20.0 17.5 15.0
* lon (lon) float32 4B 330.0
* time (time) datetime64[ns] 23kB 2013-01-01 ... 2014-12-31T18:00:00
Attributes:
long_name: 4xDaily Air temperature at sigma level 995
units: degK
precision: 2
GRIB_id: 11
GRIB_name: TMP
var_desc: Air temperature
dataset: NMC Reanalysis
level_desc: Surface
statistic: Individual Obs
parent_stat: Other
actual_range: [185.16 322.1 ]
modified_with: xarrayExercise 1#
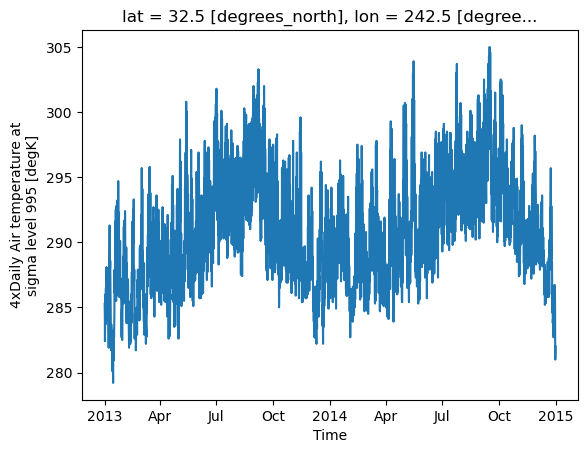
Load the air temperature dataset and plot a time-series of the temperature in San Diego (latitude 32.7157°N and longitude 117.1611°W).
ds.air.sel(lat=32.7157, lon=360-117.1611, method='nearest').plot()
[<matplotlib.lines.Line2D at 0x16d51f5e0>]
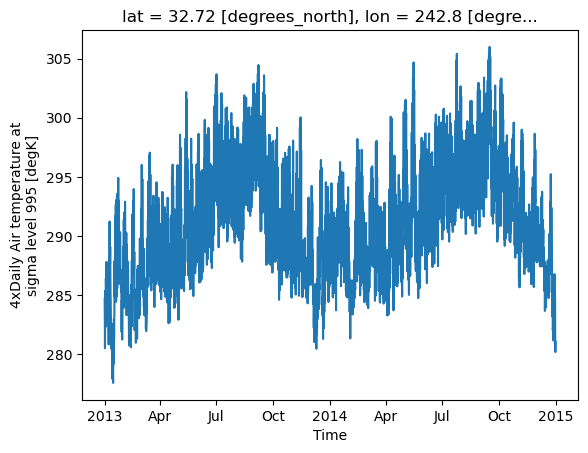
Now try using linear interpolation, does it make a difference? (You’ll have to look this up in the docs)
ds.air.interp(lat=32.7157, lon=360-117.1611).plot()
[<matplotlib.lines.Line2D at 0x17f413430>]
Reading image data#
Many applications in environmental sciences involve working with image data. Here we will briefly look at reading and manipulate image data using the Python Image Library (PIL).
Note, other useful libraries include rasterio to read and write raster data, and opencv and scikit-image for image processing. We won’t cover those here though.
from PIL import Image
img = Image.open("_images/advanced_supervised.jpg")
img

Handling PIL images#
PIL image objects have a number of useful methods and attributes. Here we’ll look at a few of them.
We can determine the image size, format, and mode using the size, format, and mode attributes, respectively:
img.size, img.format, img.mode
((787, 832), 'JPEG', 'RGB')
img.resize((800, 128))

img.resize((128, 128)).rotate(45) # degrees counter-clockwise

img.resize((128, 128)).convert('L')

Handling image data#
We can also treat these images as numpy arrays. This allows us to perform operations on the image data using numpy functions:
print(np.asarray(img).shape)
(832, 787, 3)
np.asarray(img.convert('RGBA')).shape
(832, 787, 4)
Handling image data#
Because the image is a numpy array, we can also easily treat them as xarray objects:
import xarray as xr
da_img = xr.DataArray(img, dims=("y", "x", "channel"),
coords={"y": np.arange(img.size[1], 0, -1),
"x": np.arange(img.size[0]),
"channel": ["r", "g", "b"]} )
da_img
<xarray.DataArray (y: 832, x: 787, channel: 3)> Size: 2MB
array([[[255, 255, 255],
[255, 255, 255],
[255, 255, 255],
...,
[255, 255, 255],
[255, 255, 255],
[255, 255, 255]],
[[255, 255, 255],
[255, 255, 255],
[255, 255, 255],
...,
[255, 255, 255],
[255, 255, 255],
[255, 255, 255]],
[[255, 255, 255],
[255, 255, 255],
[255, 255, 255],
...,
...
...,
[255, 255, 255],
[255, 255, 255],
[255, 255, 255]],
[[255, 255, 255],
[255, 255, 255],
[255, 255, 255],
...,
[255, 255, 255],
[255, 255, 255],
[255, 255, 255]],
[[255, 255, 255],
[255, 255, 255],
[255, 255, 255],
...,
[255, 255, 255],
[255, 255, 255],
[255, 255, 255]]], dtype=uint8)
Coordinates:
* y (y) int64 7kB 832 831 830 829 828 827 826 825 ... 8 7 6 5 4 3 2 1
* x (x) int64 6kB 0 1 2 3 4 5 6 7 8 ... 779 780 781 782 783 784 785 786
* channel (channel) <U1 12B 'r' 'g' 'b'Handling image data#
Now we can easily perform xarray operations on the image data. For example, we can calculate the variance of the image data across the channels:
da_img.std('channel').plot.imshow()
<matplotlib.image.AxesImage at 0x17f5a5780>
Or pick out specific regions:
da_img.sel(x=slice(100,200), y=slice(500,300), channel='r').plot()
<matplotlib.collections.QuadMesh at 0x16d3f9ff0>
Handling image data#
Often in our machine learning pipelines we will want to stack multiple images or data samples together. Let’s first read another example image:
img2 = Image.open("_images/supervised_general.jpg")
da_img2 = xr.DataArray(img2, dims=("y", "x", "channel"),
coords={"y": np.arange(img2.size[1], 0, -1),
"x": np.arange(img2.size[0]),
"channel": ["r", "g", "b"]} )
Now we can use the xr.concat function to stack the two images together:
X_data = xr.concat([da_img, da_img2], dim="sample")
X_data
<xarray.DataArray (sample: 2, y: 833, x: 787, channel: 3)> Size: 16MB
array([[[[255., 255., 255.],
[255., 255., 255.],
[255., 255., 255.],
...,
[255., 255., 255.],
[255., 255., 255.],
[255., 255., 255.]],
[[255., 255., 255.],
[255., 255., 255.],
[255., 255., 255.],
...,
[255., 255., 255.],
[255., 255., 255.],
[255., 255., 255.]],
[[255., 255., 255.],
[255., 255., 255.],
[255., 255., 255.],
...,
...
...,
[ nan, nan, nan],
[ nan, nan, nan],
[ nan, nan, nan]],
[[255., 255., 255.],
[255., 255., 255.],
[255., 255., 255.],
...,
[ nan, nan, nan],
[ nan, nan, nan],
[ nan, nan, nan]],
[[255., 255., 255.],
[255., 255., 255.],
[255., 255., 255.],
...,
[ nan, nan, nan],
[ nan, nan, nan],
[ nan, nan, nan]]]], dtype=float32)
Coordinates:
* y (y) int64 7kB 1 2 3 4 5 6 7 8 9 ... 826 827 828 829 830 831 832 833
* x (x) int64 6kB 0 1 2 3 4 5 6 7 8 ... 779 780 781 782 783 784 785 786
* channel (channel) <U1 12B 'r' 'g' 'b'
Dimensions without coordinates: sampleHandling missing data#
Notice that because the two images above are slightly different shapes xarray has automatically broadcast the smaller image to the larger image. This is a very useful feature of xarray that makes working with image data much easier.
In doing so, it has filled the missing data with nan values. This is a common way to handle missing data in xarray and is very useful for many applications, but it can also cause problems in ML pipelines when e.g. calculating the loss function.
The solution is very much problem dependent, but some common approaches include:
Removing the missing data, by e.g. cropping the images
Resizing the data to the same shape before concatenating them
Filling the missing data with a constant value (
da.fillna())Filling the missing data with the mean or median value (
da.fillna(da.mean()))Interpolating the missing data (
da.interpolate_na())
Data layout, one-hot encoding etc.#
Different machine learning algorithms require different data layouts. For example, many deep learning algorithms require the data to be in a specific format, such as a 4D tensor for image data. Simpler models might require the data to be in a 2D matrix format.
Again, xarray can make these conversions very easy. For example, we can easily flatten the image data to a 2D matrix:
X_data.mean('channel').stack(flatxy=("y", "x"))
<xarray.DataArray (sample: 2, flatxy: 655571)> Size: 5MB
array([[255., 255., 255., ..., nan, nan, nan],
[255., 255., 255., ..., nan, nan, nan]], dtype=float32)
Coordinates:
* flatxy (flatxy) object 5MB MultiIndex
* y (flatxy) int64 5MB 1 1 1 1 1 1 1 1 ... 833 833 833 833 833 833 833
* x (flatxy) int64 5MB 0 1 2 3 4 5 6 7 ... 780 781 782 783 784 785 786
Dimensions without coordinates: sampleOne-hot encoding#
When handling multiple classes in a classification problem, it is often useful to encode the classes as one-hot vectors. This is a vector where all elements are zero except for one element which is one.
This is in contrast to a “label” encoding where the classes are simply encoded as integers.
sklearn provides a host of useful tools for these kind of tasks which can be combined with models to form a ‘Pipeline’. These can be very powerful, but I find them quite cumbersome to work with so I often use pandas and xarray to handle these tasks instead.
One-hot encoding#
For example, we can use the pd.get_dummies function to convert a pandas series of labels to a one-hot encoded matrix:
import pandas as pd
# Sample xarray Dataset with a 'category' dimension
df = pd.DataFrame({
'data': [1, 2, 3, 1, 2, 4],
'category': ['A', 'B', 'C', 'A', 'B', 'D']
})
df
| data | category | |
|---|---|---|
| 0 | 1 | A |
| 1 | 2 | B |
| 2 | 3 | C |
| 3 | 1 | A |
| 4 | 2 | B |
| 5 | 4 | D |
# Apply one-hot encoding
encoded_df = pd.get_dummies(df, columns=['category'], dtype=int)
encoded_df
| data | category_A | category_B | category_C | category_D | |
|---|---|---|---|---|---|
| 0 | 1 | 1 | 0 | 0 | 0 |
| 1 | 2 | 0 | 1 | 0 | 0 |
| 2 | 3 | 0 | 0 | 1 | 0 |
| 3 | 1 | 1 | 0 | 0 | 0 |
| 4 | 2 | 0 | 1 | 0 | 0 |
| 5 | 4 | 0 | 0 | 0 | 1 |
One-hot encoding images#
Let’s take a look at how we can use xarray to one-hot encode image data. First, we need to load an image with multiple classes. Here we’ll use a compressed version of our test image:
da_img2_bit = xr.DataArray(img2.convert('P'), dims=("y", "x"),
coords={"y": np.arange(img2.size[1], 0, -1),
"x": np.arange(img2.size[0])} )
da_img2_bit
<xarray.DataArray (y: 833, x: 779)> Size: 649kB
array([[225, 225, 225, ..., 225, 225, 225],
[225, 225, 225, ..., 225, 225, 225],
[225, 225, 225, ..., 225, 225, 225],
...,
[225, 225, 225, ..., 225, 225, 225],
[225, 225, 225, ..., 225, 225, 225],
[225, 225, 225, ..., 225, 225, 225]], dtype=uint8)
Coordinates:
* y (y) int64 7kB 833 832 831 830 829 828 827 826 ... 8 7 6 5 4 3 2 1
* x (x) int64 6kB 0 1 2 3 4 5 6 7 8 ... 771 772 773 774 775 776 777 778One-hot encoding images#
Now we convert that to a dataframe:
df=da_img2_bit.to_dataframe(name='img')
df
| img | ||
|---|---|---|
| y | x | |
| 833 | 0 | 225 |
| 1 | 225 | |
| 2 | 225 | |
| 3 | 225 | |
| 4 | 225 | |
| ... | ... | ... |
| 1 | 774 | 225 |
| 775 | 225 | |
| 776 | 225 | |
| 777 | 225 | |
| 778 | 225 |
648907 rows × 1 columns
And then one-hot encode the data and convert it back to an xarray object:
encoded_df = pd.get_dummies(df, columns=['img'], prefix='', prefix_sep='')
encoded_ds = encoded_df.to_xarray()
encoded_ds
<xarray.Dataset> Size: 51MB
Dimensions: (y: 833, x: 779)
Coordinates:
* y (y) int64 7kB 833 832 831 830 829 828 827 826 ... 8 7 6 5 4 3 2 1
* x (x) int64 6kB 0 1 2 3 4 5 6 7 8 ... 771 772 773 774 775 776 777 778
Data variables: (12/79)
0 (y, x) bool 649kB False False False False ... False False False
11 (y, x) bool 649kB False False False False ... False False False
12 (y, x) bool 649kB False False False False ... False False False
16 (y, x) bool 649kB False False False False ... False False False
17 (y, x) bool 649kB False False False False ... False False False
18 (y, x) bool 649kB False False False False ... False False False
... ...
212 (y, x) bool 649kB False False False False ... False False False
217 (y, x) bool 649kB False False False False ... False False False
218 (y, x) bool 649kB False False False False ... False False False
219 (y, x) bool 649kB False False False False ... False False False
224 (y, x) bool 649kB False False False False ... False False False
225 (y, x) bool 649kB True True True True True ... True True True TrueOne-hot encoding images#
How do we convert the multiple data variables to a single variable with multiple dimensions?
encoded_da = encoded_ds.to_dataarray(dim='category')
# And let's also make the category an int type
encoded_da.coords['category'] = encoded_da.coords['category'].astype(int)
encoded_da
<xarray.DataArray (category: 79, y: 833, x: 779)> Size: 51MB
array([[[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False],
...,
[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False]],
[[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False],
...,
[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False]],
[[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False],
...,
...
...,
[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False]],
[[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False],
...,
[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False]],
[[ True, True, True, ..., True, True, True],
[ True, True, True, ..., True, True, True],
[ True, True, True, ..., True, True, True],
...,
[ True, True, True, ..., True, True, True],
[ True, True, True, ..., True, True, True],
[ True, True, True, ..., True, True, True]]])
Coordinates:
* y (y) int64 7kB 833 832 831 830 829 828 827 826 ... 8 7 6 5 4 3 2 1
* x (x) int64 6kB 0 1 2 3 4 5 6 7 ... 771 772 773 774 775 776 777 778
* category (category) int64 632B 0 11 12 16 17 18 ... 212 217 218 219 224 225Exercise 2#
Convert this one-hot encoded dataset back to the original image data.
encoded_da.idxmax('category')
<xarray.DataArray 'category' (y: 833, x: 779)> Size: 5MB
array([[225, 225, 225, ..., 225, 225, 225],
[225, 225, 225, ..., 225, 225, 225],
[225, 225, 225, ..., 225, 225, 225],
...,
[225, 225, 225, ..., 225, 225, 225],
[225, 225, 225, ..., 225, 225, 225],
[225, 225, 225, ..., 225, 225, 225]])
Coordinates:
* y (y) int64 7kB 833 832 831 830 829 828 827 826 ... 8 7 6 5 4 3 2 1
* x (x) int64 6kB 0 1 2 3 4 5 6 7 8 ... 771 772 773 774 775 776 777 778Data scaling and normalization#
Again, sklearn has tools and pipelines to do this, but with pandas and xarray it is very easy to do this manually:
X_scaled = (X_data.max('sample') - X_data) / (X_data.max('sample') - X_data.min('sample'))
X_scaled.min(['x', 'y', 'channel']), X_scaled.max(['x', 'y', 'channel'])
(<xarray.DataArray (sample: 2)> Size: 8B
array([0., 0.], dtype=float32)
Dimensions without coordinates: sample,
<xarray.DataArray (sample: 2)> Size: 8B
array([1., 1.], dtype=float32)
Dimensions without coordinates: sample)
X_scaled.plot.imshow(col='sample', col_wrap=2)
<xarray.plot.facetgrid.FacetGrid at 0x17f808400>
/Users/watson-parris/miniconda3/envs/sio209_dev/lib/python3.10/site-packages/matplotlib/cm.py:494: RuntimeWarning: invalid value encountered in cast
xx = (xx * 255).astype(np.uint8)
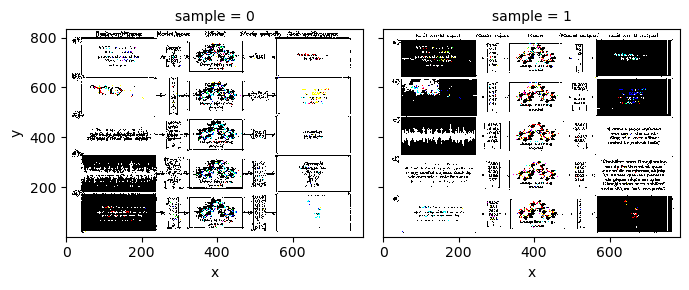
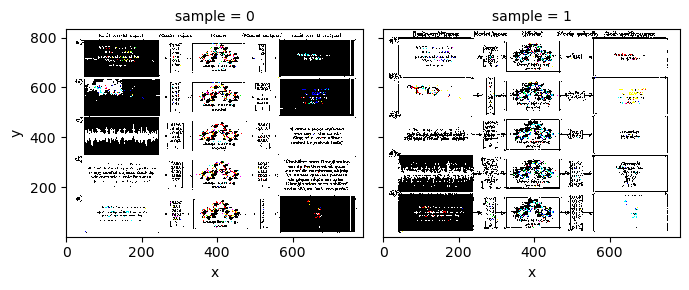
X_normed = (X_data - X_data.mean('sample')) / X_data.std('sample')
/Users/watson-parris/miniconda3/envs/sio209_dev/lib/python3.10/site-packages/numpy/lib/nanfunctions.py:1879: RuntimeWarning: Degrees of freedom <= 0 for slice.
var = nanvar(a, axis=axis, dtype=dtype, out=out, ddof=ddof,
X_scaled.mean(['x', 'y', 'channel']), X_scaled.std(['x', 'y', 'channel'])
(<xarray.DataArray (sample: 2)> Size: 8B
array([0.62178177, 0.37821826], dtype=float32)
Dimensions without coordinates: sample,
<xarray.DataArray (sample: 2)> Size: 8B
array([0.48494247, 0.48494244], dtype=float32)
Dimensions without coordinates: sample)
X_normed.plot.imshow(col='sample', col_wrap=2)
<xarray.plot.facetgrid.FacetGrid at 0x17f8e8700>
/Users/watson-parris/miniconda3/envs/sio209_dev/lib/python3.10/site-packages/matplotlib/cm.py:494: RuntimeWarning: invalid value encountered in cast
xx = (xx * 255).astype(np.uint8)
Feature selection#
In machine learning we usually have a lot of data, and not all of it is useful. Feature selection is the process of selecting a subset of relevant features for use in model construction. Feature selection techniques are used for several reasons:
simplification of models to make them easier to interpret by researchers/users,
shorter training times,
to avoid the curse of dimensionality,
to improve the accuracy of a model by removing irrelevant features or noise.
Feature selection#
There are many different feature selection techniques, but here we’ll look at a few simple ones:
Removing features with low variance
Univariate feature selection such as
SelectKBestAkaike / Bayesian information criterion (AIC / BIC)
These all make some assumptions about the data though, so it is important to understand the data and the assumptions of the feature selection technique before using it. For deep learning models, feature selection is often not necessary as the model can learn the relevant features itself.